Introduction

Overview: AvaMERG Task.
We propose the Avatar-based Multimodal Empathetic Response Generation (AvaMERG) challenge on the ACM MM platform. Unlike traditional text-only empathetic response tasks, given a multimodal dialogue context, models are expected to generate an empathetic response that includes three synchronized components: textual reply, emotive speech audio, and expressive talking face video.
Challenge Task Definition
The challenge contains two subtasks.

Task 1: Multimodal-Aware Empathetic Response Generation.
Task-1: Participants are required to develop a model capable of processing multimodal dialogue contexts and generating textual responses.

Task 2: Multimodal Empathetic Response Generation.
Task-2: Participants are required to develop a model capable of processing multimodal dialogue contexts and generating empathetic multimodal responses.
Submission
To participate in the contest, you will submit the response text or response video. As you develop your model, you can evaluate your results use automated metrics such as Distinct-n (Dist-1/2) for text and FID score for video.
After all submissions are uploaded, we will run a human-evaluation of all submitted response text and videos. Specifically, we will have human labelers compare all submitted videos to the reference videos. Labelers will evaluate videos on the following criteria:
- Empathy: How well the response shows understanding and compassion for the speaker’s emotions.
- Relevance: How relevant the response is to the input query or context.
- Multimodal Consistency: Whether the verbal, facial, and vocal expressions are consistent with each other.
- Naturalness: How natural and human-like the response appears.
We will invite the top three performing teams to submit a 6-page technical paper with up to 2 additional pages for references and appendices. After peer review, the accepted papers will be published in the conference proceedings of ACM Multimedia 2025.
Invitations will be sent out on June 18, and the submission deadline is June 30.
If you are interested in participating in this challenge, please register by filling out the form at the following link: Google Form
Dataset
The dataset for this challenge is derived from AvaMERG. It is a benchmark dataset for Avatar-based Multimodal Empathetic Response Generation. AvaMERG extended the original Empathetic Dialogue dataset by considering multimodal response.
The datasets (audio/video) have been avaliable on Hugging Face and Baidu Drive.
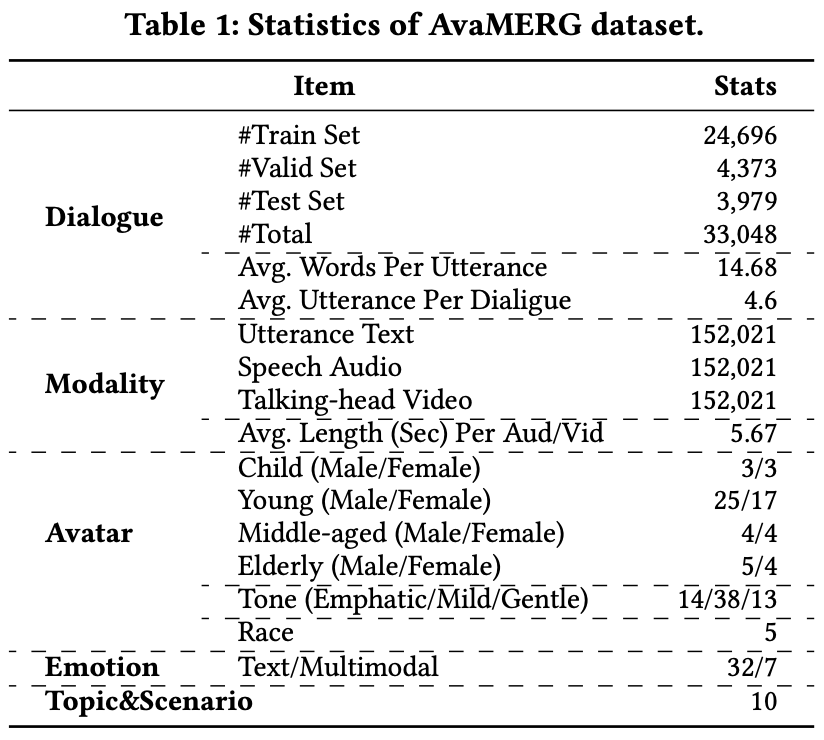
Statistics of AvaMERG are shown in the following table.
Example of a sample:
{
"conversation_id": "01118",
"speaker_profile": {
"age": "young",
"gender": "male",
"timbre": "high",
"ID": 28
},
"listener_profile": {
"age": "young",
"gender": "female",
"timbre": "mid",
"ID": 18
},
"topic": "Life Events",
"turns": [
{
"turn_id": "0",
"context": "I was shocked when the Eagles won the Super Bowl.",
"dialogue_history": [
{
"index": 0,
"role": "speaker",
"utterance": "I was shocked when the Eagles won the Super Bowl."
}
],
"response": "Yes, I think everyone was shocked! The real question is, were you happy?",
"chain_of_empathy": {
"speaker_emotion": "surprised",
"event_scenario": "The Eagles winning the Super Bowl",
"emotion_cause": "Surprise at an unexpected sports victory",
"goal_to_response": "Determining the speaker's happiness about the win"
}
},
{
"turn_id": "1",
"context": "I was shocked when the Eagles won the Super Bowl.",
"dialogue_history": [
{
"index": 0,
"role": "speaker",
"utterance": "I was shocked when the Eagles won the Super Bowl."
},
{
"index": 1,
"role": "listener",
"utterance": "Yes, I think everyone was shocked! The real question is, were you happy?"
},
{
"index": 2,
"role": "speaker",
"utterance": "I was very happy."
}
],
"response": "That's awesome.. Hopefully they win again in the future!",
"chain_of_empathy": {
"speaker_emotion": "surprised",
"event_scenario": "The Philadelphia Eagles winning the Super Bowl.",
"emotion_cause": "Unexpected victory of the Eagles in the Super Bowl.",
"goal_to_response": "Reinforcing happiness and optimism about future games."
}
}
]
},
Timeline
Please note: The submission deadline is at 11:59 p.m. (Anywhere on Earth) of the stated deadline date.
Baseline
Link to the code AvaMERG-Pipeline
Rewards
Top-ranked participants in this competition will receive a certificate of achievement and will be recommended to write a technical paper for submission to the ACM MM 2025.
Organizers
Han Zhang (Xidian University, Xi'an, China)
Hao Fei (National University of Singapore, Singapore)
Hong Han (Xidian University, Xi'an, China)
Lizi Liao (Singapore Management University, Singapore, Singapore)
Erik Cambria (Nanyang Technological University, Singapore, Singapore)
Min Zhang (Harbin Institute of Technology, Shenzhen, China)
References
[1] Zhang H, Meng Z, Luo M, et al. Towards Multimodal Empathetic Response Generation: A Rich Text-Speech-Vision Avatar-based Benchmark[C]//THE WEB CONFERENCE 2025.
[2] Li Y A, Han C, Raghavan V, et al. Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models[J]. Advances in Neural Information Processing Systems, 2023, 36: 19594-19621.
[3] Ma Y, Zhang S, Wang J, et al. DreamTalk: When Emotional Talking Head Generation Meets Diffusion Probabilistic Models[J]. arXiv preprint arXiv:2312.09767, 2023.